
はじめに
RightTouchでProduct Engineerとしてプロダクト開発を行っている吉本です。
先日、約1年半にわたって開発を続けていたプロダクトをついにリリースしました。
今回、開発メンバーを中心にリレー形式でプロダクトや開発の裏側について発信中です。
- Product Engineerの振り返り: 新規プロダクト・QANT ナレッジデスク(β)をリリースするまでの14ヶ月
- QANT ナレッジデスク(β)のロジック開発者として考えていた事
- 顧客の「リアル」を解像度高く捉える:トークスクリプト機能開発の舞台裏
本稿でもその一環として、プロダクト開発における課題への取り組みや実装の工夫を一部ご紹介します。
ナレッジとは
カスタマーサポートにおける「ナレッジ」とは、マニュアルや業務手順書のような顧客対応に必要な情報を体系的にまとめた知的資産のことを指します。
ナレッジの管理方法は各企業やセンターで様々でExcelやPDF、その他の非構造データで運用されていたり、システムで管理されていても検索性や保守性がないといった課題を抱えているケースも少なくありません。
QANTナレッジはそうしたナレッジを構造データとして一元管理し、検索性の向上と管理コストの削減を通じてカスタマーサポート業務の効率化を実現することを目的としています。
LLMを活用した自動インポート
しかし、運用中のナレッジをQANTナレッジに移管するにあたっては、人力でナレッジを登録していく必要があり、数が膨大なナレッジの初期構築コストは大きなハードルとなっています。
今回、移管作業の補助を目的としてLLMを活用した自動インポート機能の開発を行ったので、その取り組みを紹介したいと思います。
変換の流れ
QANTナレッジではエディターにTipTap(※)を採用しています。
※TipTap:Webアプリ向けの拡張性の高いリッチテキストエディタ(ProseMirrorベースのJavaScriptライブラリ)
TipTapのデータ形式はJSONあるため、最終的な変換のアウトプットはJSONを目指しました。
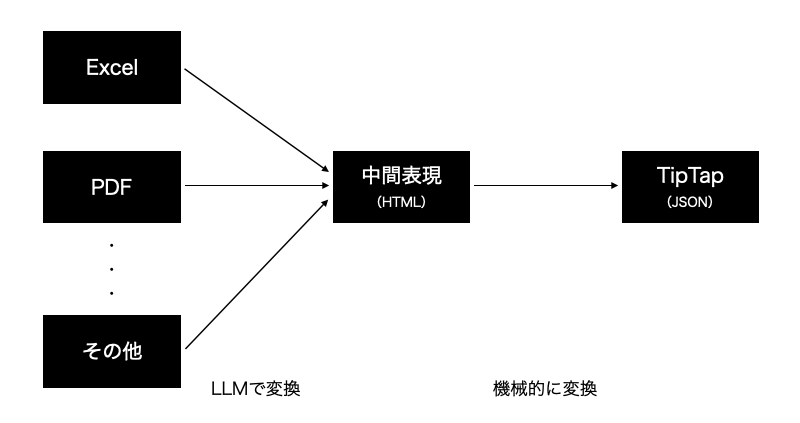
全体の流れとしては、ExcelやPDF、その他の形式のデータをLLMを活用して一律で中間表現に変換し、そこから機械的な処理でJSONを得ます。
中間表現
元データからJSONへの直接の変換はデータの抜け落ちや崩れが多く発生することが予想されました。そこで間に中間表現層を設け、見た目の再現性を極力保った形での変換を目指す上でTipTapに変換可能な意味構造を持つHTML形式をフォーマットとしました。
例えばですが、QANTナレッジ上で使える文字色には限りがあります。
なので元データの文字色に対してQANTナレッジ内では、どの色で表現するのが適切かを判断した上でその結果を中間表現に持たせる必要があります。
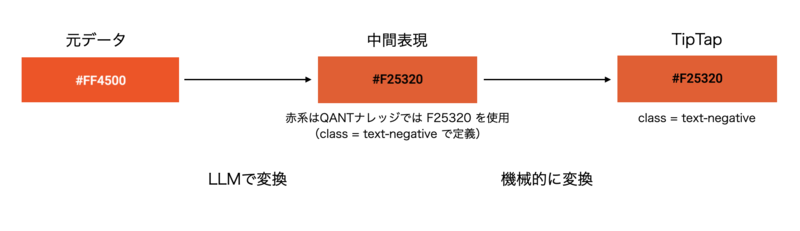
このように元データでの表現をできる限りTipTap上で保持できる形で変換をかけるための判断をLLMに担ってもらい、単純に文字列を取り込むだけでなく、段落・見出し・表・リスト・段組・画像といった「構造」と最低限の「装飾」を可能な限り保持した形で中間表現に変換します。
また、HTMLとしての中間表現を設けることでQANTナレッジにインポートする前にブラウザで簡易的に見た目の状態を確認することができ、デバッグが容易になることも大きなメリットの1つです。
本記事においては、Excel形式の元データを中間表現に変換する処理について触れていきます。
アプローチ1:画像ベースの変換
最初のアプローチでは、元のExcelデータを画像として一括変換し、その画像をLLMに渡して中間表現を生成する方法を試しました。
このアプローチの最大のメリットは、元データの形式が何であっても一度画像に変換して処理するので、画像への変換さえできればあとは一律で変換処理をかけることができるようになるということです。
処理フロー
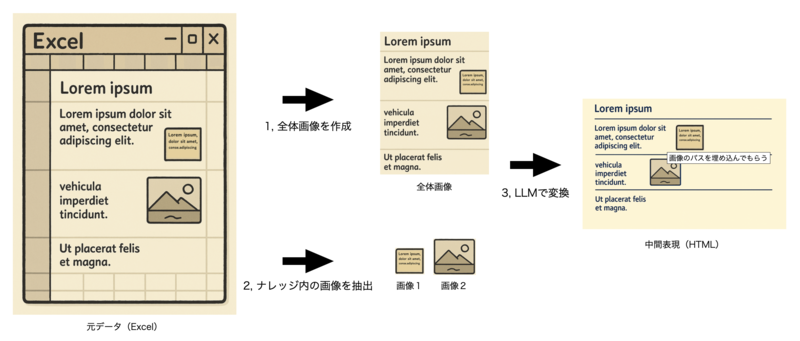
1, 全体画像に変換
元データ全体の見た目をそのまま1枚の画像として保存します。
2, ナレッジに含まれる画像や図形を個別に抽出
元データ内で画像や図形が使用されている場合はPNGデータとして抜き出します。
3, 全体画像+個別画像+プロンプトをLLMに渡して変換
全体画像をベースとして変換するよう生成を指示
また、個別画像が全体画像の中のどこで使用されているかを判別してもらい、imgタグに当該画像のパスを入れてもらう形で変換を指示していました。
結果
期待通りの変換ができているナレッジもあった一方で、以下の課題点がありました。
- 画像 / 図形周りの精度が低い
- 画像が抜けたり、画像の配置場所が違う。
- テキスト化すべき画像 / 図形とPNGのまま残すべき画像 / 図形の判別が難しい。
- 生成結果の精度の揺らぎが大きい
- 入力内容が同じでもうまくいく場合とそうでない場合がある。
特に画像の配置場所が入れ替わってしまうと、インポート後の手動での手直し時に元のナレッジとの対応関係が分かりにくくなることから構造の把握が難しくなり、一からExcelをコピペして作成するよりも手直し作業の方がコストがかかってしまうというものありました。
また、”テキストベースの画像” や ”テキストが含まれる図形” は、将来的なメンテナンス性を考えるとPNGのままではなく文字列として取り込みたいところですが、この判定精度にも課題がありました。
社内で確認会を実施した結果、修正が必要ないもしくは微修正で使用できそうなナレッジは3割程度にとどまりました。
上記の数字はあくまで変換元のデータの複雑性に大きく依存するので参考値ではあるものの、この状態ではまだまだ実用に耐えうるレベルの精度ではないという判断になりました。
アプローチ2:構造化データの抽出と段階処理による変換
アプローチ1で課題となっていた画像まわりの精度不足と変換精度の揺らぎを改善するため、方針転換することにしました。
生成がうまくいかなったナレッジに見えていた特徴として、ナレッジの下に行くほど崩れが顕著になる というものがありました。
アプローチ1ではLLMに渡す情報が画像と指示文のみだったのでLLMの判断の自由度が大きくなりすぎてしまっており、処理の途中で発生したわずかな揺らぎが後半に行くほど累積してしまっている印象を持ちました。
この問題の解消のために、構造的な手がかりを前提として与える 必要があると考え、Excelを .htm形式で保存することで得られるデータに着目しました。
このデータを活用することでLLM が判断すべき領域を最小限に抑えつつ、崩れの蓄積を防ぐアプローチへ切り替えました。
Excelを.htmで保存するとfilesディレクトリが生成され、その配下にExcelで使用されている画像や図形、.htm形式のデータがまとめて格納されます。(Windowsの場合)
処理フロー
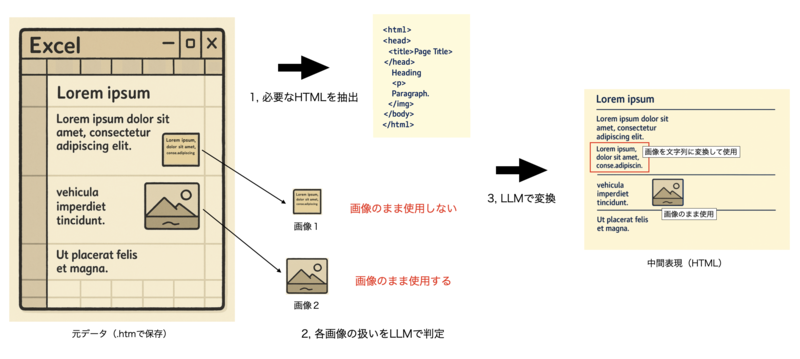
1, .htmファイルの中身を整形
Excelから出力した.htmファイルは中には数万行という余分なメタ情報を多く含むため、LLMに渡す前に見た目の再現に必要な情報だけを抽出しました。
2, 画像 / 図形の使用方針を判定
ナレッジ内で使用されている画像 / 図形のPNGデータのみをまとめてLLMに渡し、画像のまま扱うべきものか、テキストに変換したい画像かを判定させました。
精度向上のため、この処理は独立したステップとして切り出しました。
3, .LLMによる変換
整形済みのHTMLと画像の扱い方の情報をLLMに渡し、中間表現に変換してもらいます。
画像のまま使用したい部分には画像のパスを埋め込み、テキストに変換したい画像の部分にはテキスト化した状態となるようにします。
生成物の精度評価
先にも触れた通りLLM を用いる以上、同じインプットでも生成結果にはどうしても揺らぎが生じます。しかも、その揺らぎは扱うナレッジが複雑であればあるほど顕著に現れます。
そこに対する対策として、生成物の精度を簡易的にスコアリングする仕組みを導入しました。
これまでの取り組みから、画像周りの変換の難易度が最も高いことがわかっているため、画像に着目した精度のスコア化と選別を行っています。
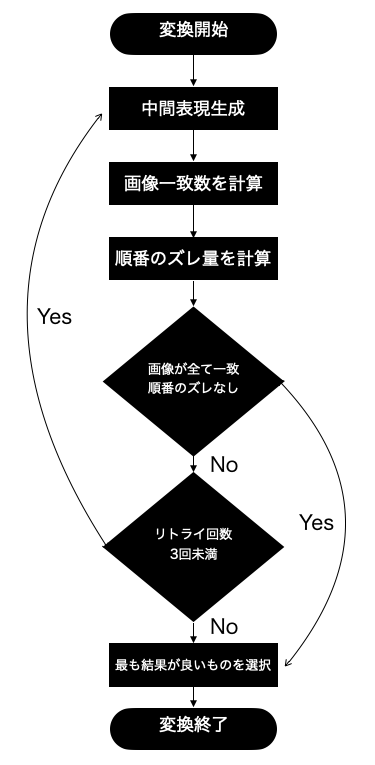
判定フロー
1, LLMを用いて中間表現を生成
2, 画像の一致数、順番のズレ量を計算(後述)
3, 一致しない画像があったり、順番にズレがある場合は生成回数最大3回までリトライ
4, 画像の一致数、順番のズレ量を元に最も良いスコアの変換結果を採用
画像一致数
- "変換前の画像名"と"変換後の画像名"の一致数
- 例:変換前の画像 5個 → 変換後に4個の画像名が一致する画像が含まれている
→ 画像一致数 = 4
順番ズレ量
- 変換前後で画像の順番がどれだけズレているかの合計値
- 画像の並び順を変換前後で比較し、位置の差の絶対値の合計を取得
例:
変換前: [image001.png, image002.png, image003.png]
変換後: [image002.png, image001.png, image003.png]indexのズレ量を計算
- image001.png: |0 - 1| = 1
- image002.png: |1 - 0| = 1
- image003.png: |2 - 2| = 0
→ 順番ズレ量 = 1 + 1 + 0 = 2
上記のように変換前後で比較した上で不整合がある場合は複数回再生成させて、最もスコアが良いものが変換精度が高い成果物であると判断して最終アウトプットにします。
これまでに取り組んだものをまとめると以下になります。
- 元データから構造化データを抜き出してプロンプトに加える
- 画像判定ステップを抜き出し、LLMの処理を分割
- スコア化により精度の揺らぎに対応
これらの取り組みにより、最初のアプローチと比べて成果物の精度を上げることができ、再度の社内確認会では修正が必要ないもしくは微修正で使用できそうなナレッジの割合を7割程度まで上げることができました。
まだまだ完璧には程遠い結果ではありますが、初期移管の工数削減に一定寄与できるものを作ることができたと思います。
感じたこと
LLM を活用した機能開発はこれまでの自分のエンジニア経験にはなく、まさに “違う属性の敵との対峙” でした。本稿で触れていない細かい苦悩や壁はたくさんあり、振り返ってみるとLLMの不確実性とどう向き合うかが最も難しかった部分だったと思います。
従来のシステム開発では、同じインプットに対して同じアウトプットが返ってくるのが前提ですがLLM はそうではありません。同じ入力でも期待通りの結果を返すこともあれば、予想外の方向に崩れることもあり、しかもその“崩れ方”すら変わることもある。
エンジニアリングの一般的な営みである「再現 → 調査 → 特定 → 解決」の流れが成り立ちにくい中で何を基準に手を打つべきか、その判断がとても難しかったです。
また、100点満点を出すことができないとわかっている中で、じゃあ何点なら合格なのかを自分たちで定義していく必要があるということが開発で発生するのもこれまでとは違うタイプの大変さでした。
これらアウトプットのブレや不確実性により溶ける時間。本開発におけるHP消費量はなかなかのものでした。
さらに、LLM の処理内容がブラックボックスであることも苦労に拍車をかけました。
運が悪いことに、開発初期にいくつかのデータを試し変換した際、「意外とうまくいくぞ?」と思わせる生成結果が出てしまいました。ところが、後になって別のデータ群を変換したときに歯が立たないケースが続出し、そこで初めて “LLMの得意・不得意の輪郭” を理解していなかったことに気づきました。
今振り返ると、うまくいかない例の炙り出しは初期段階で積極的に行っておくべきでした。
LLM は間違いなく強力な技術ですが、万能ではありません。だからこそ ”何を任せ、何を任せないか” の線引きが非常に重要だと感じました。
コンテキストが不足しているとLLMに過剰な判断領域を与えてしまい、意図しない方向へとブレやすくなる。
“いかにして LLM の判断領域を最小化するか” は、今回強く実感したポイントです。
学びも多かったものの、これまでの開発では味わったことのないタイプの苦悩や戸惑いがあり、開発中は素直に「LLM に向き合っているすべての人、本当にお疲れさまです...」という心境になったことが印象に残っています。
さいごに
Excel から Tiptap へのインポート事例を紹介しましたが、今後お客様の利用が拡大していくにつれ、扱うべきナレッジデータの多様性は一気に広がっていくはずです。
紙ベースの資料や、企業ごとに独自ルールで記述されたドキュメント、癖のあるレイアウトなど、形式のバリエーションは想像以上に幅広いでしょう。
その中で、どんな形式にも高い精度で変換できる仕組みをどう実現するか、そして スケール可能なオペレーションの仕組みをどう構築するか など、大きな課題はまだまだあります。
今回は、あくまで「初期移管」という文脈でのインポート機能の一端として紹介しました。 しかし、生成 AI の進化とともにカスタマーサポート領域の業務改善はより広く、深く求められていきます。
その未来を見据えると、外部プロダクトや各種データソースとの連携をいかにスムーズに行えるか が、ナレッジマネジメントの価値を大きく左右します。
だからこそ、非構造データをいかに構造化し、適切に取り込めるかという領域は今後も継続的に強化していく予定です。
採用情報
RightTouchでは、Product Engineerをはじめ、プロダクト価値を一緒に育てる仲間を積極採用中です。カジュアル面談も歓迎しています。ご興味があれば、ぜひ採用ページをご覧ください。